* Refactor(mail): rename paperless_mail/parsers.py → paperless/parsers/mail.py Preserve git history for MailDocumentParser by committing the rename separately before editing, following the project convention. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Refactor(mail): move mail parser tests to paperless/tests/parsers/ Move test_parsers.py → test_mail_parser.py and test_parsers_live.py → test_mail_parser_live.py alongside the other built-in parser tests, preserving git history before editing. Update MailDocumentParser import to the new canonical location. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Chore: move mail parser sample files to paperless/tests/samples/mail/ Relocate all mail test fixtures from src/paperless_mail/tests/samples/ to src/paperless/tests/samples/mail/ ahead of the parser plugin refactor. Add the new path to the codespell skip list to prevent false-positive spell corrections in binary/fixture email files. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Feat(tests): add mail parser fixtures to paperless/tests/parsers/conftest.py Add mail_samples_dir, per-file sample fixtures, and mail_parser (context-manager style) to mirror the old paperless_mail conftest but rooted at the new samples/mail/ location. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Feat(parsers): migrate MailDocumentParser to ParserProtocol Move the mail parser from paperless_mail/parsers.py to paperless/parsers/mail.py and refactor it to implement ParserProtocol: - Class-level name/version/author/url attributes - supported_mime_types() and score() classmethods (score=20) - can_produce_archive=False, requires_pdf_rendition=True - Context manager lifecycle (__enter__/__exit__) - New parse() signature without mailrule_id kwarg; consumer sets parser.mailrule_id before calling parse() instead - get_text()/get_date()/get_archive_path() accessor methods - extract_metadata() returning email headers and attachment info Register MailDocumentParser in the ParserRegistry alongside Text and Tika parsers. Update consumer, signals, and all import sites to use the new location. Update tests to use the new accessor API, patch paths, and context-manager fixture. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Fix(parsers): pop legacy constructor args in mail signal wrapper MailDocumentParser.__init__ takes no constructor args in the new protocol. Update the get_parser() signal wrapper to pop logging_group and progress_callback (passed by the legacy consumer dispatch path) before instantiating — the same pattern used by TextDocumentParser. Also update test_mail_parser_receives_mailrule to use the real signal wrapper (mail_get_parser) instead of MailDocumentParser directly, so the test exercises the actual dispatch path and matches the new parse() call signature (no mailrule kwarg). Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Bumps this so we can run * Fixes location of the fixture * Removes fixtures which were duplicated * Feat(parsers): add ParserContext and configure() to ParserProtocol Replace the ad-hoc mailrule_id attribute assignment with a typed, immutable ParserContext dataclass and a configure() method on the Protocol: - ParserContext(frozen=True, slots=True) lives in paperless/parsers/ alongside ParserProtocol and MetadataEntry; currently carries only mailrule_id but is designed to grow with output_type, ocr_mode, and ocr_language in a future phase (decoupling parsers from settings.*) - ParserProtocol.configure(context: ParserContext) -> None is the extension point; no-op by default - MailDocumentParser.configure() reads mailrule_id into _mailrule_id - TextDocumentParser and TikaDocumentParser implement a no-op configure() - Consumer calls document_parser.configure(ParserContext(...)) before parse(), replacing the isinstance(parser, MailDocumentParser) guard and the direct attribute mutation Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Feat(parsers): call configure(ParserContext()) in update_document task Apply the same new-style parser shim pattern as the consumer to update_document_content_maybe_archive_file: - Call __enter__ for Text/Tika parsers after instantiation - Call configure(ParserContext()) before parse() for all new-style parsers (mailrule_id is not available here — this is a re-process of an existing document, so the default empty context is correct) - Call parse(path, mime_type) with 2 args for new-style parsers - Call get_thumbnail(path, mime_type) with 2 args for new-style parsers - Call __exit__ instead of cleanup() in the finally block Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Fix(tests): add configure() to DummyParser and missing-method parametrize ParserProtocol now requires configure(context: ParserContext) -> None. Update DummyParser in test_registry.py to implement it, and add 'missing-configure' to the test_partial_compliant_fails_isinstance parametrize list so the new method is covered by the negative test. Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com> * Cleans up the reprocess task and generally reduces duplicate of classes * Corrects the score return * Updates so we can report a page count for these parsers, assuming we do have an archive produced when called * Increases test coverage * One more coverage * Updates typing * Updates typing --------- Co-authored-by: Claude Sonnet 4.6 <noreply@anthropic.com>
![]()


![]()
![]()

![]()
Paperless-ngx
Paperless-ngx is a document management system that transforms your physical documents into a searchable online archive so you can keep, well, less paper.
Paperless-ngx is the official successor to the original Paperless & Paperless-ng projects and is designed to distribute the responsibility of advancing and supporting the project among a team of people. Consider joining us!
Thanks to the generous folks at DigitalOcean, a demo is available at demo.paperless-ngx.com using login demo / demo. Note: demo content is reset frequently and confidential information should not be uploaded.
This project is supported by:
![]()
Features
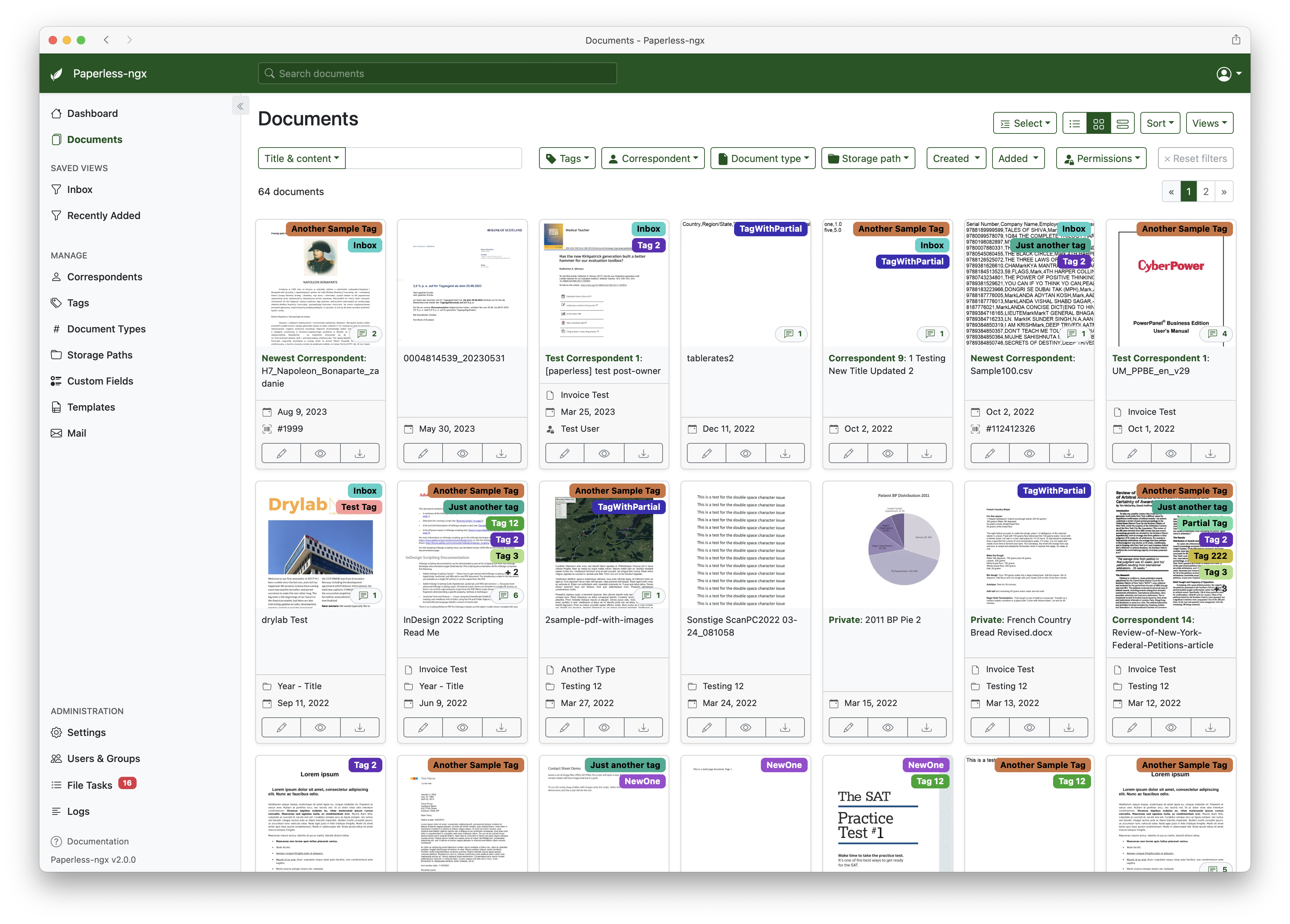
A full list of features and screenshots are available in the documentation.
Getting started
The easiest way to deploy paperless is docker compose. The files in the /docker/compose directory are configured to pull the image from the GitHub container registry.
If you'd like to jump right in, you can configure a docker compose environment with our install script:
bash -c "$(curl -L https://raw.githubusercontent.com/paperless-ngx/paperless-ngx/main/install-paperless-ngx.sh)"
More details and step-by-step guides for alternative installation methods can be found in the documentation.
Migrating from Paperless-ng is easy, just drop in the new docker image! See the documentation on migrating for more details.
Documentation
The documentation for Paperless-ngx is available at https://docs.paperless-ngx.com.
Contributing
If you feel like contributing to the project, please do! Bug fixes, enhancements, visual fixes etc. are always welcome. If you want to implement something big: Please start a discussion about that! The documentation has some basic information on how to get started.
Community Support
People interested in continuing the work on paperless-ngx are encouraged to reach out here on github and in the Matrix Room. If you would like to contribute to the project on an ongoing basis there are multiple teams (frontend, ci/cd, etc) that could use your help so please reach out!
Translation
Paperless-ngx is available in many languages that are coordinated on Crowdin. If you want to help out by translating paperless-ngx into your language, please head over to https://crowdin.com/project/paperless-ngx, and thank you! More details can be found in CONTRIBUTING.md.
Feature Requests
Feature requests can be submitted via GitHub Discussions, you can search for existing ideas, add your own and vote for the ones you care about.
Bugs
For bugs please open an issue or start a discussion if you have questions.
Related Projects
Please see the wiki for a user-maintained list of related projects and software that is compatible with Paperless-ngx.
Important Note
Document scanners are typically used to scan sensitive documents like your social insurance number, tax records, invoices, etc. Paperless-ngx should never be run on an untrusted host because information is stored in clear text without encryption. No guarantees are made regarding security (but we do try!) and you use the app at your own risk. The safest way to run Paperless-ngx is on a local server in your own home with backups in place.